同步查询
这是我们最常的调用模式,客户端调用Query[函数],发起查询命令,等待结果返回,读取结果;再发送第二条查询命令,等待结果返回,读取结果。总耗时,会是两次查询的时间之和。简化一下过程,例如下图: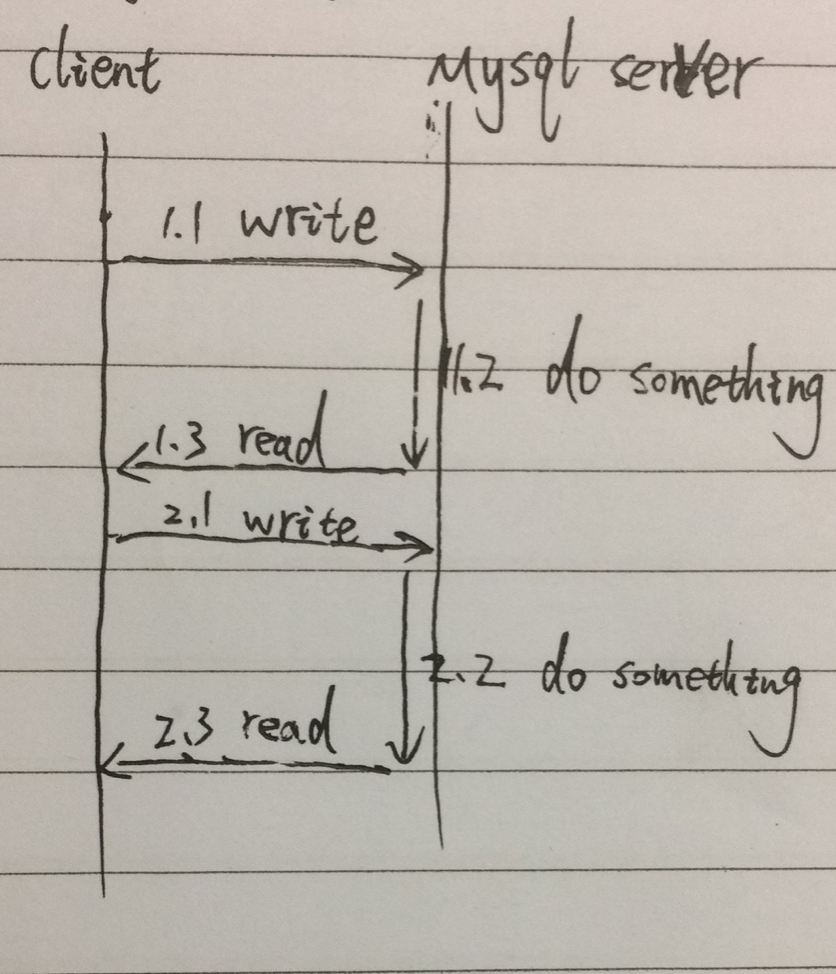
例图,由1.1到1.3为一个Query[函数]的调用,两次查询,就要串行经历1.1、1.2、1.3、2.1、2.2、2.3,尤其在1.2和2.2会阻塞等待,进程没法做其他事情。
同步调用的好处是,符合我们的直观思维,调用和处理都简单。缺点是进程阻塞在等待结果返回,增加额外的运行时间。
如果,有多条查询请求,或者进程还有其他的事情处理,那么能否把等待的时间也合理利用起来,提高进程的处理能力呢,显然是可以的。
拆分
现在,我们把Query[函数]打碎,客户端在1.1后,马上返回,客户端跳过1.2,在1.3有数据达到后再去读取数据。这样进程在原来的1.2阶段就解放了,可以做更多的事情,例如…再发起一条sql查询[2.1],是否看到了并发查询的雏形了。
并发查询
相对于同步查询的下一条查询的发起都在上一条完成后,并发查询,可以在上一条查询请求发起后,立刻发起下一条查询请求。简化一下过程,下图: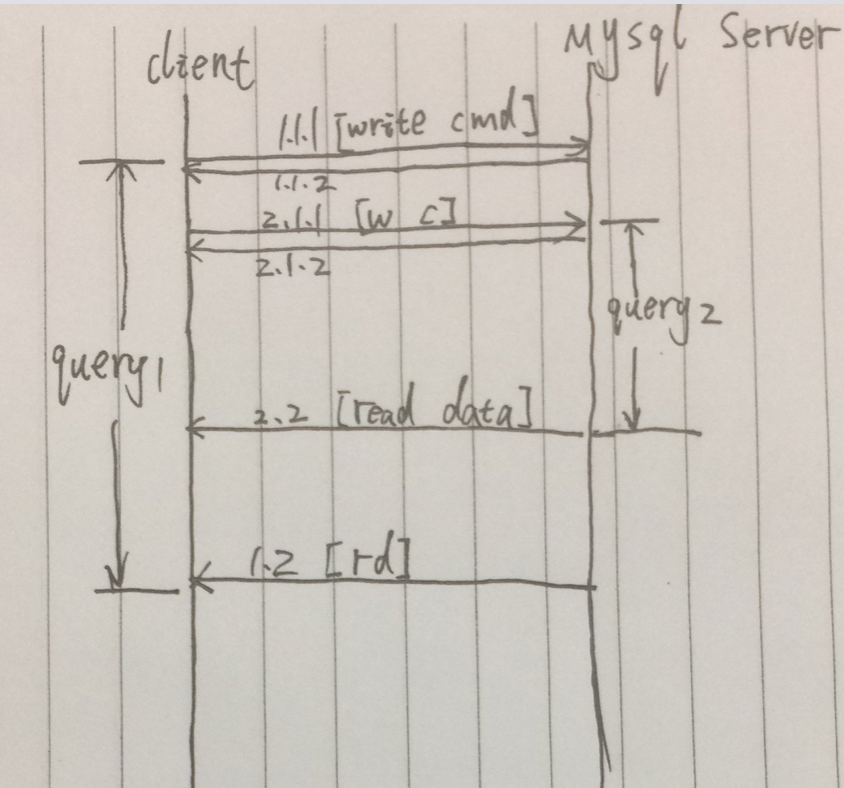
例图,在1.1.1成功发送完请求后,立马返回[1.1.2],最终查询结果的返回时在遥远的1.2 。但是在,1.1.1到1.2中间,还发起了另一个查询请求,这时间段内,就同时发起了两条查询请求,2.2先于1.2到达,那么两条查询的总耗时,只相当于第一条查询的时间。
并发查询的优点是,可以提高进程的使用率,避免阻塞等待服务器处理查询,缩短了多条查询的耗时。但缺点也很明显,发起N条并发查询,就需要建立N条数据库链接,对于有数据库连接池的应用来说,可以避免这种情况。
退化
理想情况下,我们希望并发N条查询,总耗时等于查询时间最长的一条查询。但也有可能并发查询会[退化]为[同步查询]。What?例图中,如果1.2在2.1.1前就返回了,那么并发查询就[退化]为[同步查询]了,但付出的代价却比同步查询要高。
多路复用
- 发起query1
- 发起query2
- 发起query3
- ………
- 等待query1、query2、query3
- 读取query2结果
- 读取query1结果
- 读取query3结果
那么,怎么等待知道什么时候查询结果返回了,又是哪个的查询结果返回呢?
对每个查询IO调用read?如果是遇上阻塞IO,这样就会阻塞在一个IO上,其他IO有结果返回了,也没法处理。那么,如果是非阻塞IO,那不用怕会阻塞在其中一个IO上了,确实是,但又会造成不断地轮询判断,浪费CPU资源。
对于这种情况可以使用多路复用轮询多个IO。
PHP实现并发查询MySQL
PHP的mysqli(mysqlnd驱动)提供多路复用轮询IO(mysqli_poll)和异步查询(MYSQLI_ASYNC、mysqli_reap_async_query),使用这两个特性实现并发查询,示例代码:
mysqli_poll源码:
并发查询操作结果
为了更直观地看效果,我找了一个1.3亿数据量并且没有优化过的表进行操作。
并发查询的结果: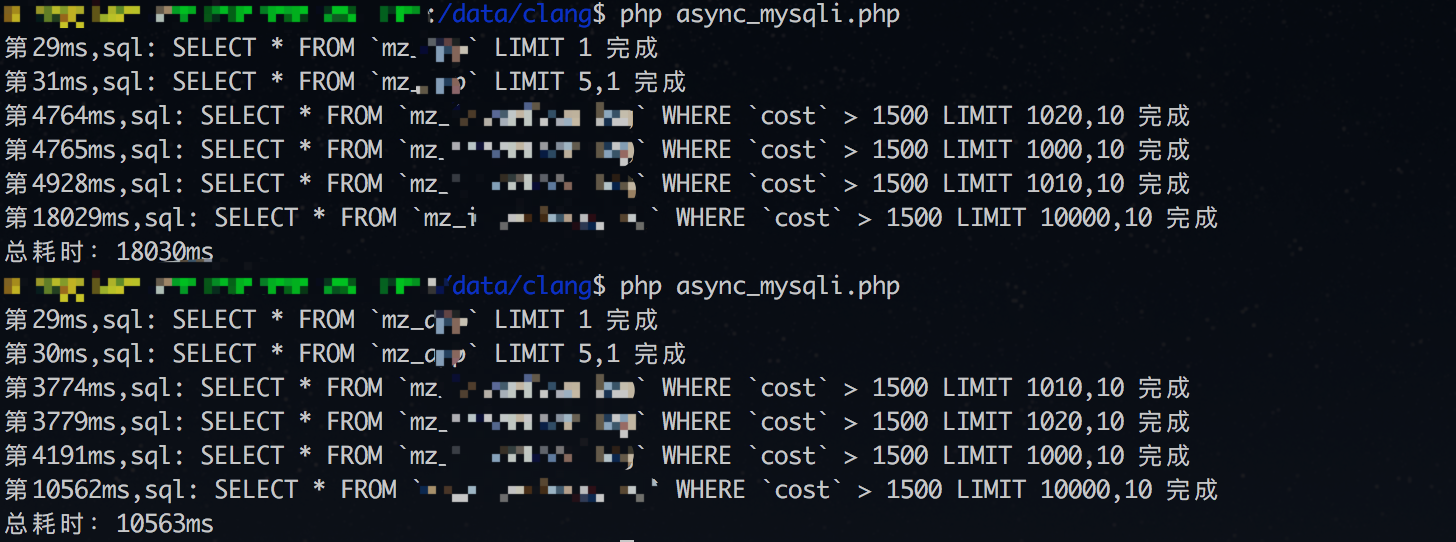
同步查询的结果:
从结果来看,同步查询的总耗时是所有查询的时间的累加;而并发查询的总耗时在这里其实是查询时间最长的那一条(同步查询的第四条,耗时是10几秒,符合并发查询的总耗时),而且并发查询的查询顺序和结果到达的顺序是不一样的。
多条耗时较短的查询对比
使用多条查询时间较短的sql进行对比一下
并发查询的测试1结果(数据库链接时间也统计进去):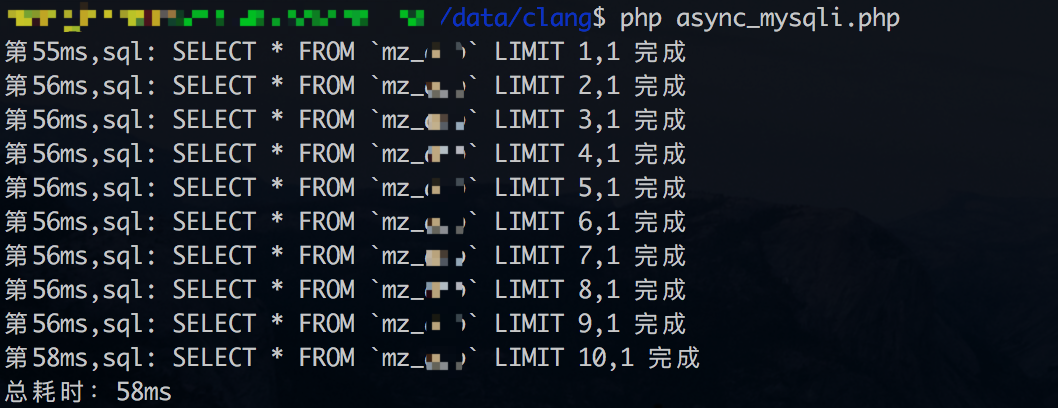
同步查询的结果(数据库链接时间也统计进去):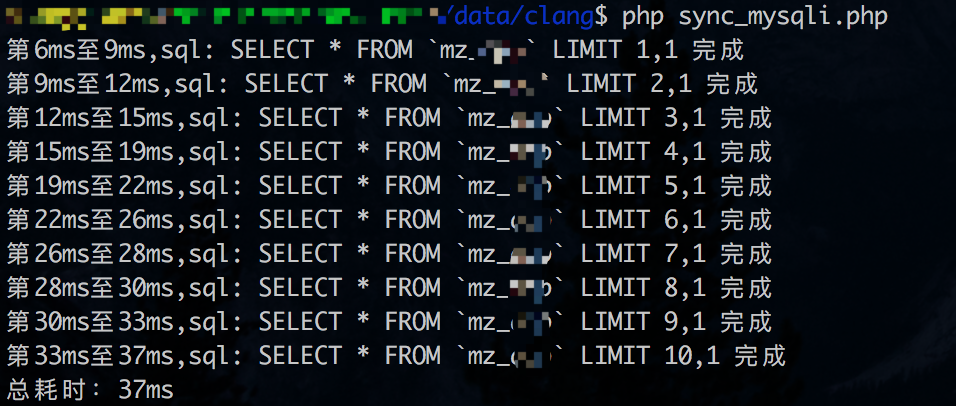
并发查询的测试2结果(不统计数据库链接时间):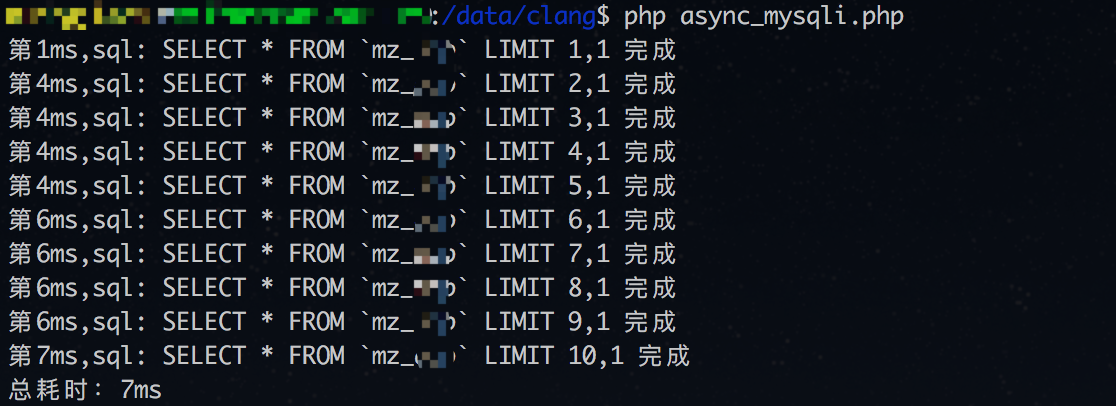
从结果上看,并发查询测试1并没有讨到好处。从同步查询上看,每条查询耗时大概3-4ms左右。但如果不把数据库链接时间统计进去(同步查询只有一次数据库链接),并发查询的优势又能体现出来了。
结语
这里探讨了一下PHP实现并发查询MySQL,从实验上结果直观地认识了并发查询的优缺点。建立数据库连接的时间在一条优化了的sql查询上,占得比重还是很大。#没有连接池,要你何用
github:PHP并发查询MySQL代码