高效定时器的实现
场景
linux crontab在实现定时任务中起到重要的作用,那如果我们去实现定时一个contab又如何实现呢?怎么样才能高效呢?本文会介绍Nginx内部的定时器的实现和golang的Tick定时器的实现。
常规思路
在一个死循环里每秒(精度为秒)去轮询查看有没有到期的任务需要执行。
问题一
有必要每秒轮询一次吗?下一秒、下下一秒、下下下一秒都不一定会有到期执行的任务,那样不就浪费了CPU了,为何不一直休眠到最近一个到期的任务的时间点,再去遍历呢?
问题二
用什么样的数据结构去存储所有任务,才能起到高效的轮询呢?用数组?每次都遍历一遍?很明显,不高效。在Nginx里,使用了红黑树,golang中使用了小堆。
golang tick实现
|
|
golang用一个timer结构体来表示一个定时任务,其中when表示到期的绝对时间戳,也是用来进行排序构建小堆的关键字段。这样子,最先到期的任务,就会是小堆堆头的那个节点了。period字段用来表示是否循环执行这个定时任务,如果是循环任务,执行完后会重新修改when为下一次执行的时间点,调整小堆。否则,把定时任务从小堆中删除。
|
|
|
|
Nginx定时器
Nginx运用定时器的地方很多,例如读取http头部超时。Nginx使用红黑树维护所有定时任务事件,进程在每次事件轮询返回后,都会检查一遍红黑树,处理过期的定时事件,设置ngx_event_t结构体里的timedout字段为1。
|
|
Nginx woker进程检查处理过期的定时事件
1234567891011121314151617181920212223242526272829303132// worker的事件和定时任务处理函数voidngx_process_events_and_timers(ngx_cycle_t *cycle){ngx_uint_t flags;ngx_msec_t timer, delta;// ...delta = ngx_current_msec;(void) ngx_process_events(cycle, timer, flags);delta = ngx_current_msec - delta;ngx_log_debug1(NGX_LOG_DEBUG_EVENT, cycle->log, 0,"timer delta: %M", delta);// 事件处理ngx_event_process_posted(cycle, &ngx_posted_accept_events);if (ngx_accept_mutex_held) {ngx_shmtx_unlock(&ngx_accept_mutex);}if (delta) {// 处理过期的定时任务ngx_event_expire_timers();}// ...}ngx_event_expire_timers过期定时任务处理
1234567891011121314151617181920212223242526272829303132333435voidngx_event_expire_timers(void){ngx_event_t *ev;ngx_rbtree_node_t *node, *root, *sentinel;sentinel = ngx_event_timer_rbtree.sentinel;// 循环查找处理当前所有过期的时间for ( ;; ) {root = ngx_event_timer_rbtree.root;if (root == sentinel) {return;}node = ngx_rbtree_min(root, sentinel); // 在红黑树种查找当前时间最小的节点if ((ngx_msec_int_t) (node->key - ngx_current_msec) > 0) {// 如果时间最小的节点都还没过期,直接返回return;}ev = (ngx_event_t *) ((char *) node - offsetof(ngx_event_t, timer));ngx_log_debug2(NGX_LOG_DEBUG_EVENT, ev->log, 0,"event timer del: %d: %M",ngx_event_ident(ev->data), ev->timer.key);ngx_rbtree_delete(&ngx_event_timer_rbtree, &ev->timer); // 把时间从红黑树种删除ev->timer_set = 0;ev->timedout = 1; // 把时间设为过期ev->handler(ev); // 回调事件处理函数}}回调事件处理函数,拿http头部处理函数(ngx_http_process_request_headers)来举例吧
12345678910111213141516171819202122static voidngx_http_process_request_headers(ngx_event_t *rev){// ...c = rev->data;r = c->data;ngx_log_debug0(NGX_LOG_DEBUG_HTTP, rev->log, 0,"http process request header line");// 如果过期了,在上一步ngx_event_expire_timers中,timedout字段会被设为1,表示头部处理超时了,就给客户端错误提示if (rev->timedout) {ngx_log_error(NGX_LOG_INFO, c->log, NGX_ETIMEDOUT, "client timed out");c->timedout = 1;// 超时,关闭链接,发送request timeout错误ngx_http_close_request(r, NGX_HTTP_REQUEST_TIME_OUT);return;}// ...}
总结
实现一个定时任务调度器,需要一个进程(线程或者协程) + 一个高效数据结构(满足高效查询、频繁插入删除),例如Nginx使用的红黑树、golang使用的小堆,或者skip list(跳跃表),跳跃表是有序链表,同时插入、删除、查找性能效率也不俗,实现起来还容易,可以考虑下。
concurrentcache--golang内存缓存
concurrentcache是什么
concurrentcache是golang版的内存缓存库,采用多Segment设计,支持不同Segment间并发写入,提高读写性能。
设想场景
内存缓存的实现,防止并发写冲突,都需要先获取写锁,再写入。如果只有一个存储空间,那么并发写入的时候只能有一个go程在操作,其他的都需要阻塞等待。为了提高并发写的性能,把存储空间切分成多个Segment,每个Segment拥有一把写锁,那样,分布在不同Segment上的写操作就可以并发执行了。concurrentcache设计就是切分多个Segment,提高些并发写的效率。
concurrentcache设计思路
|
|
写
从ConcurrentCache结构体可以看出,包含一个ConcurrentCacheSegment切片,sCount表示切片的长度,这个切片的长度,在初始化的时候就确定,不再改变。
ConcurrentCacheSegment内包含一个读写锁,写入时候根据key的hash值选取写入到哪一个Segment内,通过多Segment设计,来提高写并发效率。
读
为了提高读效率,尽可能多的减少读过程对内存缓存的修改,使用golang提供的原子操作来修改访问状态(visit、miss、hits等),遇到缓存过期的节点也不马上淘汰,因为读访问上的是读锁,要删除数据需要用到写互斥锁,这样会降低读的并发性,所以推迟删除过期的节点,当写数据,Segment的节点不够用的时候再去删除过期节点。
concurrentcache缓存淘汰方式
concurrentcache缓存淘汰方式采用随机选取3个节点,优先淘汰其中过期的一个节点(上一步说的推迟删除过期节点),如果没有过期节点就选取访问量最少(ConcurrentCacheNode结构体中的visit)的节点淘汰。这个思路是参考redis的缓存淘汰策略,redis并不是严格lru算法,采用的是随机选取样本的做法。这样做也是为了提高写性能。
concurrentcache & cache2go 性能对比
(MBP 16G版本)
concurrentcache和cache2go进行了并发下的压测对比,对比结果,concurrentcache无论是执行时间还是内存占比,都比cache2go优
concurrentcache
|
|
cache2go
|
|
PHP扩展--ratelimit本地服务器限流
应用限流
本文讲的应用限流,是限制单位时间PHP应用服务器总访问量,不针对接口,不针对个人用户。原做法,是通过Redis记录访问总量,通过过期时间淘汰(单位时间访问量清零)。做法简单,效果也不错,但缺点也明显,一次访问量判断和设置,就至少要一次网络开销(Redis Incr)。优化的思路是,可否省掉这一次Redis操作(直接去掉不限流了hahahaha)。限制总访问量,分摊到每台应用机上,不就是它们自己的指标了吗。对,那就应用服务器本地记录状态,本地判断。那本地怎么记录状态?多着,本地文件、APC缓存。但要考虑性能问题,本地文件就…当我没说过。APC不错,实现起来会复杂点,要考虑修改记录的冲突问题。
Redis 版本
下面给个Redis的简版,官方思路,但有bug123456789101112$old_count = $redis->incr($key);if($old_count == 1) { expire($key, 1); // bug.Why?如果在expire前,退出了,那么这个$key就不会过期了,至少短期内过期不了,后续达到了limit上限,服务就无法使用了。}if($old_count > $limit) { echo "1秒内太多人访问了"; return false;} else { return true;}
Redis的版本可以setnx锁来实现会更稳
我的限流PHP扩展
开头说,使用APC来实现Redis上的这个功能是可以的,只是要多的事会多点,不说了,说说APC缓存的原理吧,APC使用内存共享的来实现进程间通信,咋说,php-fpm是多进程模型,同一进程可以处理多次(不是同时处理)php请求,换句话说,php-fpm的worker进程是常驻内存的,那么,php-fpm woker进程就可以通过内存共享来达到缓存数据的功能。
那么利用内存共享不就可以在多个进程间共享本地服务器的访问量了,就可以保存访问记录了。12345678910$solt = 0; // 使用那个solt比对$limit = 100; // 每秒访问量上限$rl = new M_ratelimit($solt, $limit);if($rl->acquire()) { echo "允许访问"; return true;} else { echo "超过了{$limit}上限了"; return false;}
扩展源码
|
|
PHP并发查询MySQL
同步查询
这是我们最常的调用模式,客户端调用Query[函数],发起查询命令,等待结果返回,读取结果;再发送第二条查询命令,等待结果返回,读取结果。总耗时,会是两次查询的时间之和。简化一下过程,例如下图: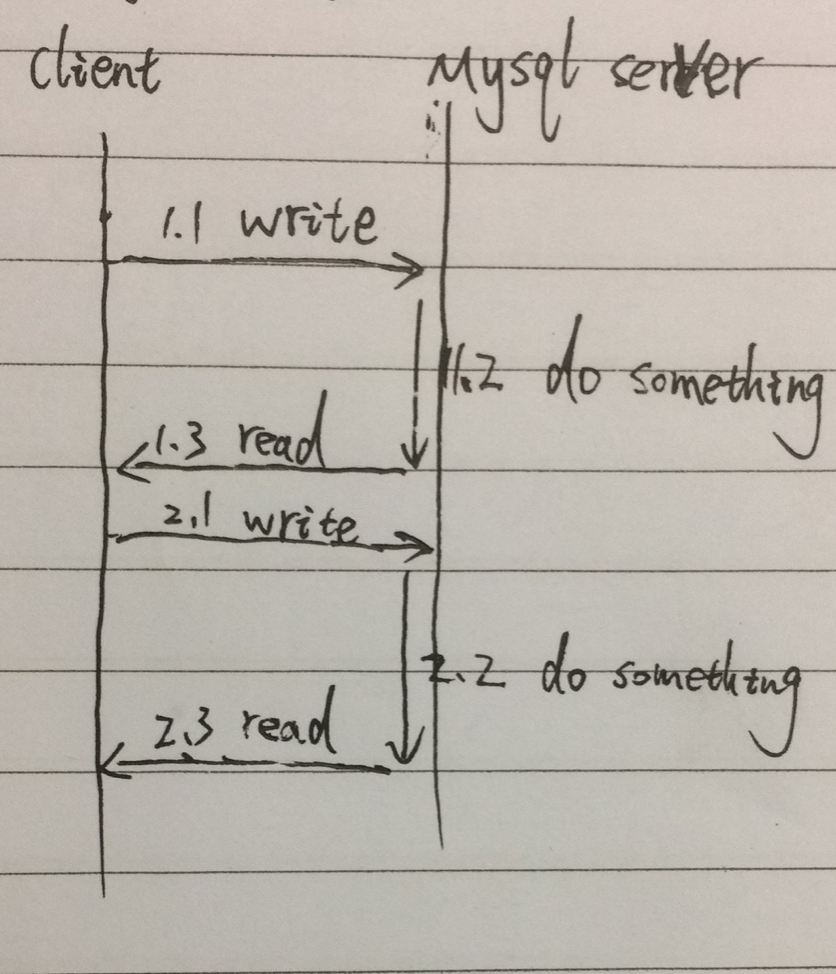
例图,由1.1到1.3为一个Query[函数]的调用,两次查询,就要串行经历1.1、1.2、1.3、2.1、2.2、2.3,尤其在1.2和2.2会阻塞等待,进程没法做其他事情。
同步调用的好处是,符合我们的直观思维,调用和处理都简单。缺点是进程阻塞在等待结果返回,增加额外的运行时间。
如果,有多条查询请求,或者进程还有其他的事情处理,那么能否把等待的时间也合理利用起来,提高进程的处理能力呢,显然是可以的。
拆分
现在,我们把Query[函数]打碎,客户端在1.1后,马上返回,客户端跳过1.2,在1.3有数据达到后再去读取数据。这样进程在原来的1.2阶段就解放了,可以做更多的事情,例如…再发起一条sql查询[2.1],是否看到了并发查询的雏形了。
并发查询
相对于同步查询的下一条查询的发起都在上一条完成后,并发查询,可以在上一条查询请求发起后,立刻发起下一条查询请求。简化一下过程,下图: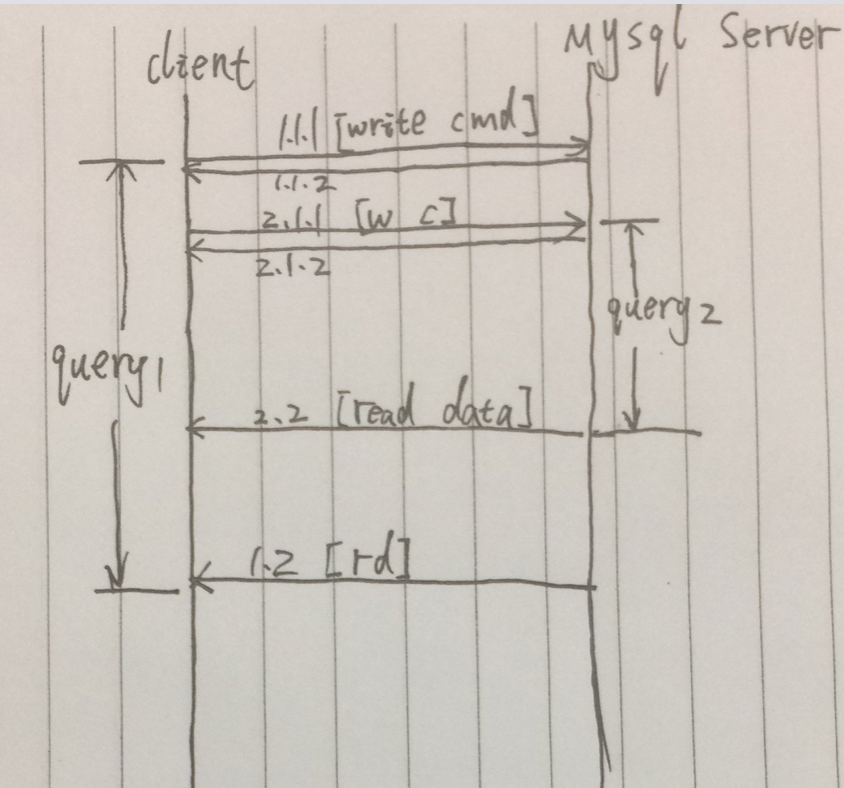
例图,在1.1.1成功发送完请求后,立马返回[1.1.2],最终查询结果的返回时在遥远的1.2 。但是在,1.1.1到1.2中间,还发起了另一个查询请求,这时间段内,就同时发起了两条查询请求,2.2先于1.2到达,那么两条查询的总耗时,只相当于第一条查询的时间。
并发查询的优点是,可以提高进程的使用率,避免阻塞等待服务器处理查询,缩短了多条查询的耗时。但缺点也很明显,发起N条并发查询,就需要建立N条数据库链接,对于有数据库连接池的应用来说,可以避免这种情况。
退化
理想情况下,我们希望并发N条查询,总耗时等于查询时间最长的一条查询。但也有可能并发查询会[退化]为[同步查询]。What?例图中,如果1.2在2.1.1前就返回了,那么并发查询就[退化]为[同步查询]了,但付出的代价却比同步查询要高。
多路复用
- 发起query1
- 发起query2
- 发起query3
- ………
- 等待query1、query2、query3
- 读取query2结果
- 读取query1结果
- 读取query3结果
那么,怎么等待知道什么时候查询结果返回了,又是哪个的查询结果返回呢?
对每个查询IO调用read?如果是遇上阻塞IO,这样就会阻塞在一个IO上,其他IO有结果返回了,也没法处理。那么,如果是非阻塞IO,那不用怕会阻塞在其中一个IO上了,确实是,但又会造成不断地轮询判断,浪费CPU资源。
对于这种情况可以使用多路复用轮询多个IO。
PHP实现并发查询MySQL
PHP的mysqli(mysqlnd驱动)提供多路复用轮询IO(mysqli_poll)和异步查询(MYSQLI_ASYNC、mysqli_reap_async_query),使用这两个特性实现并发查询,示例代码:123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566 $sqls = array( 'SELECT * FROM `mz_table_1` LIMIT 1000,10', 'SELECT * FROM `mz_table_1` LIMIT 1010,10', 'SELECT * FROM `mz_table_1` LIMIT 1020,10', 'SELECT * FROM `mz_table_1` LIMIT 10000,10', 'SELECT * FROM `mz_table_2` LIMIT 1', 'SELECT * FROM `mz_table_2` LIMIT 5,1' ); $links = []; $tvs = microtime(); $tv = explode(' ', $tvs); $start = $tv[1] * 1000 + (int)($tv[0] * 1000); // 链接数据库,并发起异步查询 foreach ($sqls as $sql) { $link = mysqli_connect('127.0.0.1', 'root', 'root', 'dbname', '3306'); $link->query($sql, MYSQLI_ASYNC); // 发起异步查询,立即返回 $links[$link->thread_id] = $link; } $llen = count($links); $process = 0; do { $r_array = $e_array = $reject = $links; // 多路复用轮询IO if(!($ret = mysqli_poll($r_array, $e_array, $reject, 2))) { continue; } // 读取有结果返回的查询,处理结果 foreach ($r_array as $link) { if ($result = $link->reap_async_query()) { print_r($result->fetch_row()); if (is_object($result)) mysqli_free_result($result); } else { } // 操作完后,把当前数据链接从待轮询集合中删除 unset($links[$link->thread_id]); $link->close(); $process++; } foreach ($e_array as $link) { die; } foreach ($reject as $link) { die; } }while($process < $llen); $tvs = microtime(); $tv = explode(' ', $tvs); $end = $tv[1] * 1000 + (int)($tv[0] * 1000); echo $end - $start,PHP_EOL;
mysqli_poll源码:12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485/* {{{ mysqlnd_poll */PHPAPI enum_func_statusmysqlnd_poll(MYSQLND **r_array, MYSQLND **e_array, MYSQLND ***dont_poll, long sec, long usec, int * desc_num){ struct timeval tv; struct timeval *tv_p = NULL; fd_set rfds, wfds, efds; php_socket_t max_fd = 0; int retval, sets = 0; int set_count, max_set_count = 0; DBG_ENTER("_mysqlnd_poll"); if (sec < 0 || usec < 0) { php_error_docref(NULL, E_WARNING, "Negative values passed for sec and/or usec"); DBG_RETURN(FAIL); } FD_ZERO(&rfds); FD_ZERO(&wfds); FD_ZERO(&efds); // 从所有mysqli链接中获取socket链接描述符 if (r_array != NULL) { *dont_poll = mysqlnd_stream_array_check_for_readiness(r_array); set_count = mysqlnd_stream_array_to_fd_set(r_array, &rfds, &max_fd); if (set_count > max_set_count) { max_set_count = set_count; } sets += set_count; } // 从所有mysqli链接中获取socket链接描述符 if (e_array != NULL) { set_count = mysqlnd_stream_array_to_fd_set(e_array, &efds, &max_fd); if (set_count > max_set_count) { max_set_count = set_count; } sets += set_count; } if (!sets) { php_error_docref(NULL, E_WARNING, *dont_poll ? "All arrays passed are clear":"No stream arrays were passed"); DBG_ERR_FMT(*dont_poll ? "All arrays passed are clear":"No stream arrays were passed"); DBG_RETURN(FAIL); } PHP_SAFE_MAX_FD(max_fd, max_set_count); // select轮询阻塞时间 if (usec > 999999) { tv.tv_sec = sec + (usec / 1000000); tv.tv_usec = usec % 1000000; } else { tv.tv_sec = sec; tv.tv_usec = usec; } tv_p = &tv; // 轮询,等待多个IO可读,php_select是select的宏定义 retval = php_select(max_fd + 1, &rfds, &wfds, &efds, tv_p); if (retval == -1) { php_error_docref(NULL, E_WARNING, "unable to select [%d]: %s (max_fd=%d)", errno, strerror(errno), max_fd); DBG_RETURN(FAIL); } if (r_array != NULL) { mysqlnd_stream_array_from_fd_set(r_array, &rfds); } if (e_array != NULL) { mysqlnd_stream_array_from_fd_set(e_array, &efds); } // 返回可操作的IO数量 *desc_num = retval; DBG_RETURN(PASS);}
并发查询操作结果
为了更直观地看效果,我找了一个1.3亿数据量并且没有优化过的表进行操作。
并发查询的结果: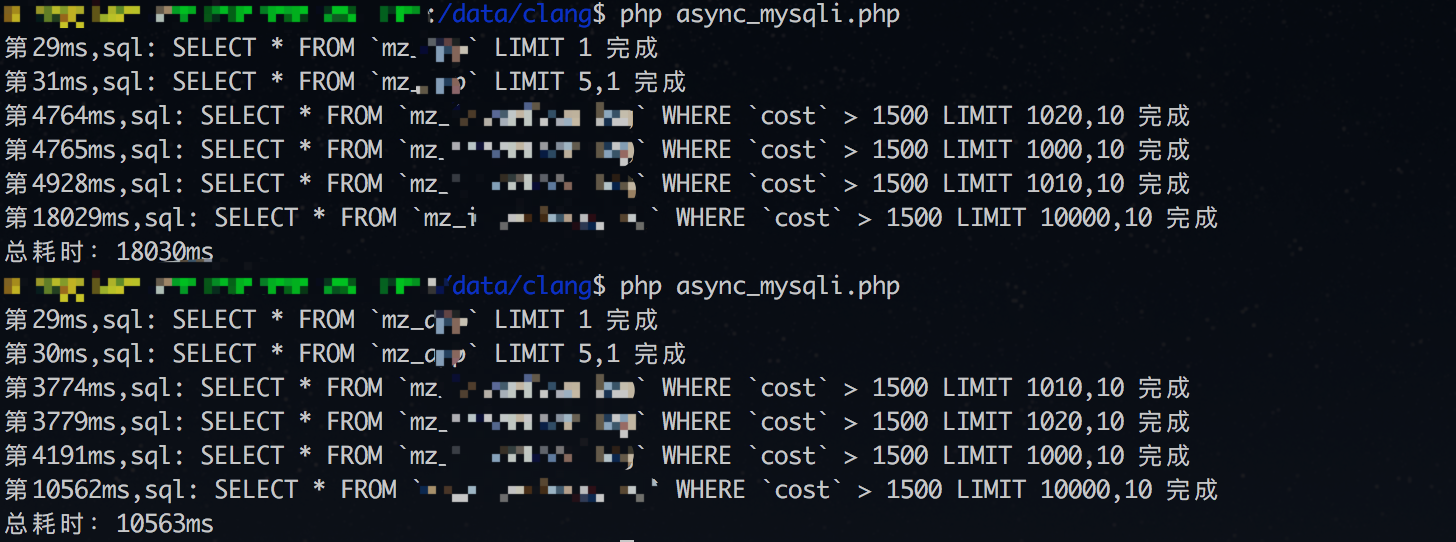
同步查询的结果:
从结果来看,同步查询的总耗时是所有查询的时间的累加;而并发查询的总耗时在这里其实是查询时间最长的那一条(同步查询的第四条,耗时是10几秒,符合并发查询的总耗时),而且并发查询的查询顺序和结果到达的顺序是不一样的。
多条耗时较短的查询对比
使用多条查询时间较短的sql进行对比一下
并发查询的测试1结果(数据库链接时间也统计进去):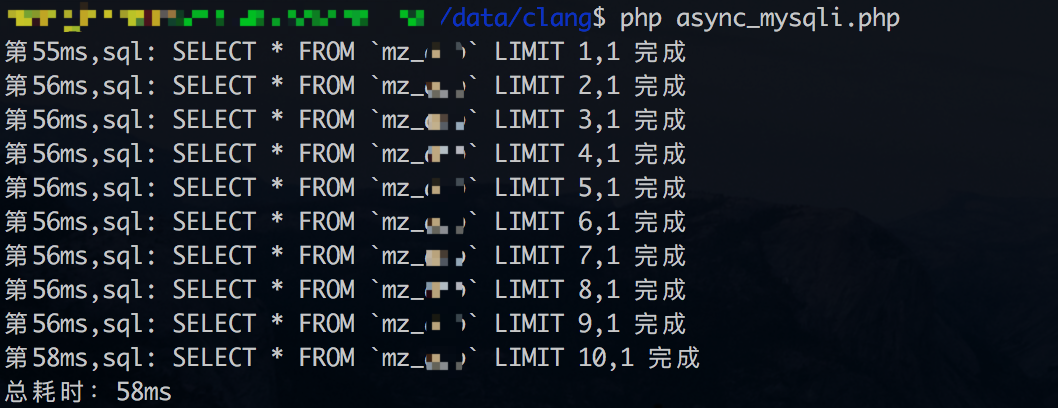
同步查询的结果(数据库链接时间也统计进去):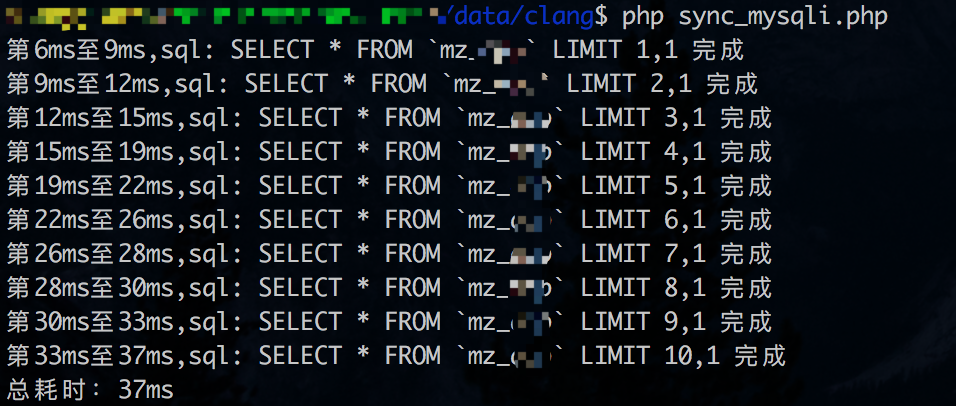
并发查询的测试2结果(不统计数据库链接时间):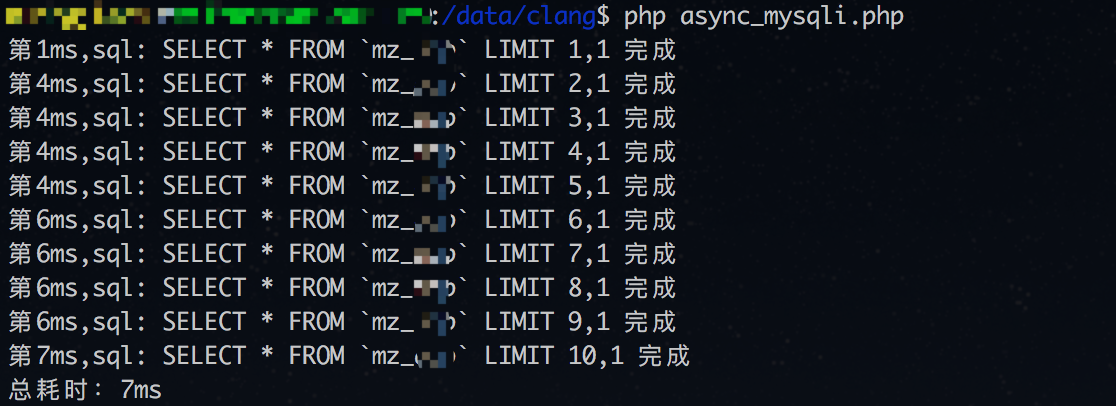
从结果上看,并发查询测试1并没有讨到好处。从同步查询上看,每条查询耗时大概3-4ms左右。但如果不把数据库链接时间统计进去(同步查询只有一次数据库链接),并发查询的优势又能体现出来了。
结语
这里探讨了一下PHP实现并发查询MySQL,从实验上结果直观地认识了并发查询的优缺点。建立数据库连接的时间在一条优化了的sql查询上,占得比重还是很大。#没有连接池,要你何用
github:PHP并发查询MySQL代码
Redis AOF
AOF
AOF是Redis的一种持久化方式,另一种是RDB。AOF通过追加写命令到文件实现持久化存储,Redis需要恢复的数据,按顺序逐条执行文件中的命令来实现恢复。
追加写命令到AOF文件
Redis执行完写命令后,把命令添加到aof_buf缓冲区中,在下一次事件轮询开始前(或者定时任务)根据指定的策略,把aof_buf缓冲区的命令写入到文件,刷新到磁盘。
appendfsync always 总是把缓冲区的数据写入文件并调用系统的fsync方法刷新到磁盘
appendfsync everysec 把缓冲区的数据写入文件,每秒执行一次fsync方法刷新到磁盘
appendfsync no 把缓冲区的数据写入文件,不会主动调用fsync方法刷新到磁盘,交由操作系统处理
第一:执行完写命令后,把命令添加到aof_buf缓冲区中:1234567891011121314151617181920212223242526272829303132333435363738394041424344454647void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc, int flags){ if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF) // 在命令执行完后调用 feedAppendOnlyFile(cmd,dbid,argv,argc); if (flags & PROPAGATE_REPL) replicationFeedSlaves(server.slaves,dbid,argv,argc);}void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) { sds buf = sdsempty(); robj *tmpargv[3]; // 构建要写入aof_buf缓冲区的数据 if (dictid != server.aof_selected_db) { char seldb[64]; snprintf(seldb,sizeof(seldb),"%d",dictid); buf = sdscatprintf(buf,"*2\r\n$6\r\nSELECT\r\n$%lu\r\n%s\r\n", (unsigned long)strlen(seldb),seldb); server.aof_selected_db = dictid; } if (cmd->proc == expireCommand || cmd->proc == pexpireCommand || cmd->proc == expireatCommand) { buf = catAppendOnlyExpireAtCommand(buf,cmd,argv[1],argv[2]); } else if (cmd->proc == setexCommand || cmd->proc == psetexCommand) { tmpargv[0] = createStringObject("SET",3); tmpargv[1] = argv[1]; tmpargv[2] = argv[3]; buf = catAppendOnlyGenericCommand(buf,3,tmpargv); decrRefCount(tmpargv[0]); buf = catAppendOnlyExpireAtCommand(buf,cmd,argv[1],argv[2]); } else { buf = catAppendOnlyGenericCommand(buf,argc,argv); } // 如果开启了aof功能,把命令添加到aof_buf缓冲区 if (server.aof_state == AOF_ON) server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf)); // 如果子进程开启了AOF文件重写,父进程会把这个最新的命令写到重写缓冲区,并发送给子进程,后话 if (server.aof_child_pid != -1) aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf)); sdsfree(buf);}
第二:根据指定的策略,把aof_buf缓冲区的命令写入到文件,刷新到磁盘123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354// redis在进入下一次事件轮询(或者定时任务)前执行以下方法flushAppendOnlyFile(0);void flushAppendOnlyFile(int force) { ssize_t nwritten; int sync_in_progress = 0; mstime_t latency; // 如果AOF缓冲区空,直接返回 if (sdslen(server.aof_buf) == 0) return; // 如果选择了,每秒调用一次fsync刷新磁盘数据,获取刷新磁盘任务状态 if (server.aof_fsync == AOF_FSYNC_EVERYSEC) sync_in_progress = bioPendingJobsOfType(BIO_AOF_FSYNC) != 0; if (server.aof_fsync == AOF_FSYNC_EVERYSEC && !force) { if (sync_in_progress) { if (server.aof_flush_postponed_start == 0) { server.aof_flush_postponed_start = server.unixtime; return; } else if (server.unixtime - server.aof_flush_postponed_start < 2) { return; } server.aof_delayed_fsync++; serverLog(LL_NOTICE,"Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis."); } } // 把aof_buf缓冲区的数据写入到文件 latencyStartMonitor(latency); nwritten = write(server.aof_fd,server.aof_buf,sdslen(server.aof_buf)); latencyEndMonitor(latency); // 如果是appendfsync always策略,那么每次都会调用aof_fsync把数据刷入到磁盘 // aof_fsync是一个宏定义 if (server.aof_fsync == AOF_FSYNC_ALWAYS) { latencyStartMonitor(latency); aof_fsync(server.aof_fd); /* Let's try to get this data on the disk */ latencyEndMonitor(latency); latencyAddSampleIfNeeded("aof-fsync-always",latency); server.aof_last_fsync = server.unixtime; } else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC && server.unixtime > server.aof_last_fsync)) { // 如果是appendfsync everysec,那么把任务添加到任务队列,由一个后台线程来执行aof_fsync if (!sync_in_progress) aof_background_fsync(server.aof_fd); server.aof_last_fsync = server.unixtime; }}
AOF重写
随着写命令不断累积,AOF文件会不断地增长,这时候Redis会执行重写,合并一些命令,举个例子,连续多条incr key命令,最终都可以合并成一条set key num的命令,大大地减少AOF文件的大小。同时,命令减少了,也可以提高Redis恢复的速度。
如何重写
AOF重写,是通过把Redis内存中的数据“翻译”成一条条命令写入到新AOF文件,而不是拿旧的AOF文件做文章,那如何“翻译”呢,看源码说事。
启动一个子进程,有子进程执行AOF文件重写123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184int rewriteAppendOnlyFileBackground(void) { pid_t childpid; long long start; if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR; // 创建多个管道,用于父进程向子进程发送最新的写命令 if (aofCreatePipes() != C_OK) return C_ERR; start = ustime(); // 创建一个子进程,由子进程执行AOF重写 if ((childpid = fork()) == 0) { char tmpfile[256]; /* Child */ closeListeningSockets(0); redisSetProcTitle("redis-aof-rewrite"); snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int) getpid()); // 开始“翻译”redis内存中的数据,重写AOF文件 if (rewriteAppendOnlyFile(tmpfile) == C_OK) { size_t private_dirty = zmalloc_get_private_dirty(); if (private_dirty) { serverLog(LL_NOTICE, "AOF rewrite: %zu MB of memory used by copy-on-write", private_dirty/(1024*1024)); } exitFromChild(0); } else { exitFromChild(1); } } else { /* Parent */ server.stat_fork_time = ustime()-start; server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */ latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000); if (childpid == -1) { serverLog(LL_WARNING, "Can't rewrite append only file in background: fork: %s", strerror(errno)); return C_ERR; } serverLog(LL_NOTICE, "Background append only file rewriting started by pid %d",childpid); server.aof_rewrite_scheduled = 0; server.aof_rewrite_time_start = time(NULL); server.aof_child_pid = childpid; updateDictResizePolicy(); server.aof_selected_db = -1; replicationScriptCacheFlush(); return C_OK; } return C_OK; }int rewriteAppendOnlyFile(char *filename) { snprintf(tmpfile,256,"temp-rewriteaof-%d.aof", (int) getpid()); fp = fopen(tmpfile,"w"); server.aof_child_diff = sdsempty(); rioInitWithFile(&aof,fp); if (server.aof_rewrite_incremental_fsync) rioSetAutoSync(&aof,AOF_AUTOSYNC_BYTES); // 对所有DB执行 for (j = 0; j < server.dbnum; j++) { char selectcmd[] = "*2\r\n$6\r\nSELECT\r\n"; redisDb *db = server.db+j; dict *d = db->dict; if (dictSize(d) == 0) continue; di = dictGetSafeIterator(d); if (!di) { fclose(fp); return C_ERR; } // 循环当前DB内的所有key while((de = dictNext(di)) != NULL) { sds keystr; robj key, *o; long long expiretime; keystr = dictGetKey(de); o = dictGetVal(de); initStaticStringObject(key,keystr); expiretime = getExpire(db,&key); // 已经过期的数据就不需要在写进文件了 if (expiretime != -1 && expiretime < now) continue; // 一下分支就是“翻译”五种数据类型的数据,把它们从db里的形式翻译成命令 // 后面挑hash和字符串的来看一下怎么“翻译” if (o->type == OBJ_STRING) { char cmd[]="*3\r\n$3\r\nSET\r\n"; if (rioWrite(&aof,cmd,sizeof(cmd)-1) == 0) goto werr; if (rioWriteBulkObject(&aof,&key) == 0) goto werr; if (rioWriteBulkObject(&aof,o) == 0) goto werr; } else if (o->type == OBJ_LIST) { if (rewriteListObject(&aof,&key,o) == 0) goto werr; } else if (o->type == OBJ_SET) { if (rewriteSetObject(&aof,&key,o) == 0) goto werr; } else if (o->type == OBJ_ZSET) { if (rewriteSortedSetObject(&aof,&key,o) == 0) goto werr; } else if (o->type == OBJ_HASH) { if (rewriteHashObject(&aof,&key,o) == 0) goto werr; } else { serverPanic("Unknown object type"); } // 如果有过期时间,写入过期时间 if (expiretime != -1) { char cmd[]="*3\r\n$9\r\nPEXPIREAT\r\n"; if (rioWrite(&aof,cmd,sizeof(cmd)-1) == 0) goto werr; if (rioWriteBulkObject(&aof,&key) == 0) goto werr; if (rioWriteBulkLongLong(&aof,expiretime) == 0) goto werr; } // 在子进程重写AOF文件过程中,父进程依旧在接收客户端的写命令 // 子进程每重写1024*10字节数据,就读一遍管道,接收父进程发送过来的最新的写命令 if (aof.processed_bytes > processed+1024*10) { processed = aof.processed_bytes; aofReadDiffFromParent(); } } dictReleaseIterator(di); di = NULL; } // 把DB内的数据“翻译”完,写进到AOF文件,并刷新到磁盘 if (fflush(fp) == EOF) goto werr; if (fsync(fileno(fp)) == -1) goto werr; // 最后的最后在停止接收父进程的最新写命令前,再接收一波父进程发送过来的最新写命令 int nodata = 0; mstime_t start = mstime(); while(mstime()-start < 1000 && nodata < 20) { if (aeWait(server.aof_pipe_read_data_from_parent, AE_READABLE, 1) <= 0) { nodata++; continue; } nodata = 0; aofReadDiffFromParent(); } // 子进程通过管道向父进程发送指令,停止接收父进程发送过来的最新命令 // 父进程在接收到该指令后,再接收到客户端的写命令,也不会再发送给子进程了,但这部分命令会在子进程结束后,父进程来写入到最新的AOF文件 if (write(server.aof_pipe_write_ack_to_parent,"!",1) != 1) goto werr; if (anetNonBlock(NULL,server.aof_pipe_read_ack_from_parent) != ANET_OK) goto werr; if (syncRead(server.aof_pipe_read_ack_from_parent,&byte,1,5000) != 1 || byte != '!') goto werr; serverLog(LL_NOTICE,"Parent agreed to stop sending diffs. Finalizing AOF..."); aofReadDiffFromParent(); serverLog(LL_NOTICE, "Concatenating %.2f MB of AOF diff received from parent.", (double) sdslen(server.aof_child_diff) / (1024*1024)); // 子进程把从父进程接收到的最新命令,追加到子进程重写完的AOF文件 if (rioWrite(&aof,server.aof_child_diff,sdslen(server.aof_child_diff)) == 0) goto werr; // 刷入到磁盘 if (fflush(fp) == EOF) goto werr; if (fsync(fileno(fp)) == -1) goto werr; if (fclose(fp) == EOF) goto werr; // 至此,子进程工作完成,返回后退出,剩余的交由父进程处理 if (rename(tmpfile,filename) == -1) { serverLog(LL_WARNING,"Error moving temp append only file on the final destination: %s", strerror(errno)); unlink(tmpfile); return C_ERR; } serverLog(LL_NOTICE,"SYNC append only file rewrite performed"); return C_OK;werr: serverLog(LL_WARNING,"Write error writing append only file on disk: %s", strerror(errno)); fclose(fp); unlink(tmpfile); if (di) dictReleaseIterator(di); return C_ERR;}
重写过程如何处理新到达的写命令
重写过程中,父进程会继续接收客户端命令,并把新的命令通过管道发送给子进程。123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172// 该方法在AOF重写过程中,父进程把新命令添加到AOF重写缓冲区,并通过管道发送给子进程void aofRewriteBufferAppend(unsigned char *s, unsigned long len) { listNode *ln = listLast(server.aof_rewrite_buf_blocks); aofrwblock *block = ln ? ln->value : NULL; while(len) { if (block) { unsigned long thislen = (block->free < len) ? block->free : len; if (thislen) { /* The current block is not already full. */ memcpy(block->buf+block->used, s, thislen); block->used += thislen; block->free -= thislen; s += thislen; len -= thislen; } } if (len) { /* First block to allocate, or need another block. */ int numblocks; block = zmalloc(sizeof(*block)); block->free = AOF_RW_BUF_BLOCK_SIZE; block->used = 0; listAddNodeTail(server.aof_rewrite_buf_blocks,block); numblocks = listLength(server.aof_rewrite_buf_blocks); if (((numblocks+1) % 10) == 0) { int level = ((numblocks+1) % 100) == 0 ? LL_WARNING : LL_NOTICE; serverLog(level,"Background AOF buffer size: %lu MB", aofRewriteBufferSize()/(1024*1024)); } } } // 父进程新增一个写事件,通过管道发送给子进程 if (aeGetFileEvents(server.el,server.aof_pipe_write_data_to_child) == 0) { aeCreateFileEvent(server.el, server.aof_pipe_write_data_to_child, AE_WRITABLE, aofChildWriteDiffData, NULL); }}void aofChildWriteDiffData(aeEventLoop *el, int fd, void *privdata, int mask) { listNode *ln; aofrwblock *block; ssize_t nwritten; UNUSED(el); UNUSED(fd); UNUSED(privdata); UNUSED(mask); while(1) { ln = listFirst(server.aof_rewrite_buf_blocks); block = ln ? ln->value : NULL; // 如果接收到子进程停止接收最新命令的请求,父进程就删除写管道事件,并不再把AOF重写缓冲区的最新命令发送给子进程 if (server.aof_stop_sending_diff || !block) { aeDeleteFileEvent(server.el,server.aof_pipe_write_data_to_child, AE_WRITABLE); return; } if (block->used > 0) { // 通过管道发送最新命令给子进程 nwritten = write(server.aof_pipe_write_data_to_child, block->buf,block->used); if (nwritten <= 0) return; memmove(block->buf,block->buf+nwritten,block->used-nwritten); block->used -= nwritten; } if (block->used == 0) listDelNode(server.aof_rewrite_buf_blocks,ln); }}
重写完成后
子进程重写完AOF文件后,就退出,由父进程做收尾的工作,例如:在子进程重写的最后会要求父进程停止发送最新命令,这之后AOF重写缓冲区还存在或者又积累了客户端发送过来的新命令,这些都由父进程来重写到新的AOF文件。123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112void backgroundRewriteDoneHandler(int exitcode, int bysignal) { if (!bysignal && exitcode == 0) { int newfd, oldfd; char tmpfile[256]; long long now = ustime(); mstime_t latency; serverLog(LL_NOTICE, "Background AOF rewrite terminated with success"); // 打开新的AOF文件 latencyStartMonitor(latency); snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int)server.aof_child_pid); newfd = open(tmpfile,O_WRONLY|O_APPEND); if (newfd == -1) { serverLog(LL_WARNING, "Unable to open the temporary AOF produced by the child: %s", strerror(errno)); goto cleanup; } // 父进程把重写缓冲区剩余的命令重写到新的AOF文件 if (aofRewriteBufferWrite(newfd) == -1) { serverLog(LL_WARNING, "Error trying to flush the parent diff to the rewritten AOF: %s", strerror(errno)); close(newfd); goto cleanup; } latencyEndMonitor(latency); latencyAddSampleIfNeeded("aof-rewrite-diff-write",latency); serverLog(LL_NOTICE, "Residual parent diff successfully flushed to the rewritten AOF (%.2f MB)", (double) aofRewriteBufferSize() / (1024*1024)); if (server.aof_fd == -1) { oldfd = open(server.aof_filename,O_RDONLY|O_NONBLOCK); } else { oldfd = -1; } // 用新的AOF文件替换旧的AOF文件 latencyStartMonitor(latency); if (rename(tmpfile,server.aof_filename) == -1) { serverLog(LL_WARNING, "Error trying to rename the temporary AOF file %s into %s: %s", tmpfile, server.aof_filename, strerror(errno)); close(newfd); if (oldfd != -1) close(oldfd); goto cleanup; } latencyEndMonitor(latency); latencyAddSampleIfNeeded("aof-rename",latency); if (server.aof_fd == -1) { close(newfd); } else { // 根据策略,刷新AOF文件到磁盘 oldfd = server.aof_fd; server.aof_fd = newfd; if (server.aof_fsync == AOF_FSYNC_ALWAYS) aof_fsync(newfd); else if (server.aof_fsync == AOF_FSYNC_EVERYSEC) aof_background_fsync(newfd); server.aof_selected_db = -1; aofUpdateCurrentSize(); server.aof_rewrite_base_size = server.aof_current_size; sdsfree(server.aof_buf); server.aof_buf = sdsempty(); } server.aof_lastbgrewrite_status = C_OK; serverLog(LL_NOTICE, "Background AOF rewrite finished successfully"); /* Change state from WAIT_REWRITE to ON if needed */ if (server.aof_state == AOF_WAIT_REWRITE) server.aof_state = AOF_ON; /* Asynchronously close the overwritten AOF. */ if (oldfd != -1) bioCreateBackgroundJob(BIO_CLOSE_FILE,(void*)(long)oldfd,NULL,NULL); serverLog(LL_VERBOSE, "Background AOF rewrite signal handler took %lldus", ustime()-now); } else if (!bysignal && exitcode != 0) { /* SIGUSR1 is whitelisted, so we have a way to kill a child without * tirggering an error conditon. */ if (bysignal != SIGUSR1) server.aof_lastbgrewrite_status = C_ERR; serverLog(LL_WARNING, "Background AOF rewrite terminated with error"); } else { server.aof_lastbgrewrite_status = C_ERR; serverLog(LL_WARNING, "Background AOF rewrite terminated by signal %d", bysignal); }cleanup: aofClosePipes(); aofRewriteBufferReset(); aofRemoveTempFile(server.aof_child_pid); server.aof_child_pid = -1; server.aof_rewrite_time_last = time(NULL)-server.aof_rewrite_time_start; server.aof_rewrite_time_start = -1; /* Schedule a new rewrite if we are waiting for it to switch the AOF ON. */ if (server.aof_state == AOF_WAIT_REWRITE) server.aof_rewrite_scheduled = 1;}
Redis源码——内存淘汰机制
Redis缓存淘汰策略
noeviction:内存达到了上限,不淘汰内存数据,遇到大部分写命令返回Out Of Memory错误。
allkeys-lru:在所有的key的哈希表中随机选择多个key,在选择到的key中使用lru算法淘汰最近最少使用的缓存。
volatile-lru:在设置了过期时间的哈希表里面随机选择多个key,在选择到的key中使用lru算法淘汰最近最少使用的缓存。
allkeys-random:在所有的key的哈希表中随机选择一个key淘汰掉。
volatile-random:在设置了过期时间的哈希表里面随机选择一个key淘汰掉。
volatile-ttl:在设置了过期时间的哈希表里面随机选择多个key,在挑选到的key中选择过期时间最小的一个淘汰掉。
LRU算法
lru算法原理,根据数据的访问时间,选择淘汰最长时间未被使用的数据。可以使用链表来实现,新增数据(访问数据),把这数据插入(移动)到链表头部,淘汰数据就选择链表末尾的数据淘汰掉。
Redis采样淘汰
Redis实现的lru淘汰算法,选择被淘汰的key不一定是所有key中最近最少使用的,只是选取的样本中访问时间距离当前时间最远的。Redis有个maxmemory-samples配置项,当Redis内存使用达到上限后,从对应哈希表中挑选设置样本数量的key,插入或者替换到样本集中,最后对样本集使用lru算法,淘汰最长时间未被使用的数据。
Redis在随机采样集中应用lru淘汰数据,而不是类似memcached那样严格地挑选所有key中最近最少访问的数据。第一是考虑到Redis内部db的实现方式,Redis是使用hash表结构实现key的存储,要实现严格的lru,那么Redis就要额外的实现一个访问时间链表,增加内存开销(Redis对内存使用还是很抠门的,很多地方都牺牲时间来换取更少的空间开销),这说法是来自官网的,并且每次读写操作都需要维护更新访问时间链表;第二考虑操作的时间开销,实现严格的lru算法,那样淘汰数据的时候都需要扫描整个哈希表(前提是基于当前的数据结构来说),扫描所有key,这样付出的时间开销不言而喻。
Redis缓存淘汰源码分析
|
|
Redis主从复制——Slave视角
Redis主从复制
为了提高性能和系统可用,Redis都会做主从复制,一来可以分担主库压力,二来在主库挂掉的时候从库依旧可以提供服务。Redis的主从复制是异步复制,返回结果给客户端和同步命令到从库是两回事,互不相干,主库也不关心从库的执行结果,对于同步命令执行的结果,从库会直接丢弃并不返回给主库。Redis的主从复制简单高效,但也不太算可靠。
Redis的主从复制是异步复制;全量同步(或增量同步)+命令传播
Slave Server
流程
Slave Server启动初始化配置,根据slaveof配置设置Slave Server的主库host(masterhost)和Slave Server的同步状态(repl_state),和所有Server一样监听客户端链接,开启后台任务。
后台定时任务包含,触发AOF重写、RDB快照、redis监控、状态收集、主从同步相关定时任务等
主从同步后台定时任务包含,从库连接主库、从库重连主库、从库给主库发送同步进度、主库向从库发送心跳包、主库删除超时从库、主库清除同步缓冲区、主库刷新从库状态等
从库连接主库
从库链接主库后,开启同步前的准备和交互,同时从库伴随着和主库交互变换自身状态。下面源代码看一下整个流程(代码有删减)1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677void syncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask) { /* * 从库和主库tcp握手成功后,从库的同步状态由REPL_STATE_CONNECT => REPL_STATE_CONNECTING * 从库向主库发送PING确保可以进行同步操作 * 发送PING,等待接收PONG */ if (server.repl_state == REPL_STATE_CONNECTING) { // 修改同步状态 REPL_STATE_CONNECTING => REPL_STATE_RECEIVE_PONG server.repl_state = REPL_STATE_RECEIVE_PONG; err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"PING",NULL); } /* * 接收PONG响应,并修改状态 REPL_STATE_RECEIVE_PONG => REPL_STATE_SEND_AUTH */ if (server.repl_state == REPL_STATE_RECEIVE_PONG) { err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL); server.repl_state = REPL_STATE_SEND_AUTH; } /* * 以下有多个类似分支,例如: * 发送身份验证信息 * 从库同步的端口、IP等信息给主库 * 就跳过不罗列了,直接到 同步命令的分支 */ /* * 从库会先尝试增量同步(发送psync命令+当前同步的进度repl_offset),这种情况是在从库和主库网络闪断后进行; * 换句话说,如果从库第一次连接主库,那么增量同步是不存在的(毕竟你之前就没有同步过,哪来的增量啊); * 还有一种情况,如果从库同步进度落后主库同步缓冲区(repl_backlog)太多,也会进行全量同步,具体后话说明 * 增量同步失败,master会返回"+FULLRESYNC"给slave ,告诉slave即将进行全量同步 */ if (server.repl_state == REPL_STATE_SEND_PSYNC) { // 发送增量同步请求命令 if (slaveTryPartialResynchronization(fd,0) == PSYNC_WRITE_ERROR) { err = sdsnew("Write error sending the PSYNC command."); goto write_error; } server.repl_state = REPL_STATE_RECEIVE_PSYNC; return; } /* * 接收增量同步请求结果 * 如果是全量同步,master会返回"+FULLRESYNC"给slave ,psync_result等于PSYNC_FULLRESYNC,接着跳到最后设置回调方法readSyncBulkPayload,等待master同步数据 */ psync_result = slaveTryPartialResynchronization(fd,1); if (psync_result == PSYNC_WAIT_REPLY) return; /* Try again later... */ /* * 不支持增量同步,即不支持psync命令,Redis2.8以上才支持 * 就进行全量同步,发送sync命令 */ if (psync_result == PSYNC_NOT_SUPPORTED) { // 发送sync命令 if (syncWrite(fd,"SYNC\r\n",6,server.repl_syncio_timeout*1000) == -1) { } } /* * 发送完同步命令后,回调readSyncBulkPayload方法获取主库回复同步数据 */ if (aeCreateFileEvent(server.el,fd, AE_READABLE,readSyncBulkPayload,NULL) == AE_ERR) { } /* * 修改同步状态为REPL_STATE_TRANSFER,即同步数据传输状态 */ server.repl_state = REPL_STATE_TRANSFER; return;}
以上代码有点长,总结一下步骤:1)slave发送自身信息到master;2)尝试增量同步,成功则等待master回送同步数据;3)不支持增量同步或者增量同步失败,则进行全量同步,并等待master回送同步数据。
全量同步(主库基于Disk-backed模式)
1、从库发送sync命令给主库(2.8以上Redis直接使用psync命令)发起全量同步,并等待数据返回
2、主库接收到命令(或者尝试增量同步失败后),把内存数据保存到rdb文件并把文件内容发送给从库
3、从库接收同步数据并保存到本地rdb文件,最后把rdb文件内容写入到内存数据库,至此全量同步完成
以上是简述一下同步流程,但其中并不止那么简单,例如:同时多个slave发起全量同步请求,主库也只会进行一次bgsave,保存内存快照到rdb文件。
rdb是redis持久化的一种,是当前redis内存数据的快照。所以全量同步,主库发送给从库的是,是内存中每一个key和它对应的value(key => value)。
以下源码分析第三步操作(代码有删减)12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455void readSyncBulkPayload(aeEventLoop *el, int fd, void *privdata, int mask) { // 读取第一行,获取同步数据量的大小 if (server.repl_transfer_size == -1) { if (strncmp(buf+1,"EOF:",4) == 0 && strlen(buf+5) >= CONFIG_RUN_ID_SIZE) { } else { // 同步数据量的大小 server.repl_transfer_size = strtol(buf+1,NULL,10); } return; } // 读取数据 nread = read(fd,buf,readlen); // 更新最后同步通信时间 server.repl_transfer_lastio = server.unixtime; // 保存数据到本地rdb文件 if (write(server.repl_transfer_fd,buf,nread) != nread) { } if (eof_reached) { // 从rdb文件中载入数据到内存 serverLog(LL_NOTICE, "MASTER <-> SLAVE sync: Loading DB in memory"); if (rdbLoad(server.rdb_filename) != C_OK) { } // 同步完后,slave修改主库信息,开始接收主库命令扩散 replicationCreateMasterClient(server.repl_transfer_s); serverLog(LL_NOTICE, "MASTER <-> SLAVE sync: Finished with success"); } return;}/* * 同步完后,slave修改主库信息,开始接收主库命令扩散 */void replicationCreateMasterClient(int fd) { server.master = createClient(fd); // 这里设置监听接收主库的发送的数据 server.master->flags |= CLIENT_MASTER; server.master->authenticated = 1; server.repl_state = REPL_STATE_CONNECTED; // 修改从库同步状态 /* * reploff和replrunid这两个是增量同步的必要参数 */ server.master->reploff = server.repl_master_initial_offset; // master的同步缓冲区的总量(当前从库同步进度) memcpy(server.master->replrunid, server.repl_master_runid, sizeof(server.repl_master_runid)); // 保存主库runid}
增量同步
全量同步可以看出存在它的缺点,那就是效率,主从都要进行文件读写,而且还要传输全部数据,其中部分已经在从库中,这部分数据就会显得有点多余了。增量同步,同步的内容也和全量同步有所区别。
全量同步,同步的数据是每一个key和它对应的value(key => value);而增量同步,同步的数据是命令,是从库未执行的命令,例如:set key1 value1 。
执行增量同步的条件:
1)从库已经和该主库进行过一次全量同步
2)主从网络超时(repl_timeout默认是60秒)重连后
3)从库同步进度(reploff)存在并且没有落后于该主库同步缓冲区
|
|
命令传播
完成全量同步(增量同步)后,主库接受客户端命令,修改了数据,为了保持主从数据一致,这些命令也需要在从库上执行一遍,哪怎么操作呢?当然不是客户端逐一修改所有从库了,而是由主库执行命令成功后,异步地把命令发送给所有从库。
这部分主要工作在于主库,就不说了,下一篇主库角度再说。从库接收主库的命令传播,其实和其他客户端的命令一样的行为,只是从库会判断是否来自主库发送的命令,更新自己同步进度,主库不关心从库执行命令的结果,所以从库也不会发送执行结果给主库,省略了一次网络IO。
心跳检测
开篇我们说过,Redis会有个定时任务在后台执行,从库会每秒向主库发送ack+同步进度;主库也会定时发送PING命令检测它所有从库的存活。1234567891011121314151617/* * 从库会每秒向主库发送ack+同步进度 * psync ack repl_off */if (server.masterhost && server.master && !(server.master->flags & CLIENT_PRE_PSYNC)) replicationSendAck();/* * 主库定时发送PING命令检测它所有从库的存活 */if ((replication_cron_loops % server.repl_ping_slave_period) == 0) { ping_argv[0] = createStringObject("PING",4); replicationFeedSlaves(server.slaves, server.slaveseldb, ping_argv, 1); decrRefCount(ping_argv[0]);}
风险
Redis的主从复制是很高效,也没有太多花哨的东西,基于异步同步,客户端不需要等待同步结果,但是也是这样的高效同步带来一些风险。
1)主库发送仅且发送一次命令给从库,如果超时,命令丢失,从库没有接收到,会造成不一致;
2)从库内存满了,主库也没法知道,而且从库收到命令传播依旧会更新自己同步进度;
3)异步复制带来的同步间隙,造成短时间内不一致,这点要根据具体业务处理;
4)客户端修改从库数据,也会导致主从不一致,可以把从库设置成只读;
废话
从库未全量同步过
Slave:Master,我要增量同步(psync ? -1)
Master:EXO ME?你没全量同步过,不行,你必须全量同步
Slave:好的,师父。全量同步
Master:同意。等着吧。
(Slave等啊等)
Master:接着,rdb
Slave:收!
(Slave全量同步完后,上线工作了,命令传播)
Master:这是我刚执行完的命令,你执行一下
Slave:好的(执行完了也不告诉你)
Master:这是我刚执行完的命令,你执行一下
Slave:好的(执行完了也不告诉你)
……
主从网络断开重连后
Slave:师父,刚掉线了,我是不是错过了什么,我要增量同步一下(psync Master_id repl_off)
Master:刚哪浪去了?问你又不答我。行了,增量同步一下吧,等着
Slave:好的,师父。
(Slave等啊等)
Master:接着,这些都是你刚没有执行的命令
Slave:收!
(Slave增量同步完后,上线工作了,命令传播)
Master:这是我刚执行完的命令,你执行一下
Slave:好的(执行完了也不告诉你)
Master:这是我刚执行完的命令,你执行一下
Slave:好的(执行完了也不告诉你)
……
主从网络断开重连后,slave落后太多
Slave:师父,刚掉线了,我是不是错过了什么,我要增量同步一下(psync Master_id repl_off)
Master:刚哪浪去了?问你又不答我。不行不行,你落后了(repl_off进度太旧了),你先全量一下我们在聊吧
Slave:好的,师父。全量同步
Master:同意。等着吧。
(Slave等啊等)
Master:接着,rdb
Slave:收!
(Slave全量同步完后,上线工作了,命令传播)
Master:这是我刚执行完的命令,你执行一下
Slave:好的(执行完了也不告诉你)
Master:这是我刚执行完的命令,你执行一下
Slave:好的(执行完了也不告诉你)
……
PHP源码阅读strtr
strtr
转换字符串中特定的字符,但是这个函数使用的方式多种。1234echo strtr('hello world', 'hw', 'ab'); // 第一种 aello borldecho strtr('hello world', 'hw', 'a'); // 第二种 aello worldecho strtr('hello world', ['hello' => 'hi']); // 第三种 hi worldecho strtr('hello world', ['he' => 'th', 'hello' => 'hi']); // 第四种 hi world
时间复杂度
O(n),最差是O(n*m)
源码
以下根据每种情况逐一分析源码。
第一种、第二种,也是最常用的,但第二种,只有’h’转换成’a’,’w’没有被处理。这种方式的替换,会以短的一方为准。如果from和to其中一个是空串,会直接返回原字符串。12345678RETURN_STR(php_strtr_ex(str, Z_STRVAL_P(from), to, MIN(Z_STRLEN_P(from), to_len)));// 从源码MIN(Z_STRLEN_P(from), to_len))可以看出来,以from、to两个字符串短的为准,剩余的会被忽略掉,所以可以解释第二种情况'w'被忽略掉// 同理,以下to中的'b'也会被忽略掉strtr('hello world', 'h', 'ab'); // aello world
接着,我们主要看下php_strtr_ex方法,是怎么实现字符转换。源码是使用hash表实现,hash表把from的每个字符,一一对应为to的相应位置的字符。123456789101112131415161718192021222324252627static zend_string *php_strtr_ex(zend_string *str, char *str_from, char *str_to, size_t trlen){ // trlen的值就是MIN(Z_STRLEN_P(from), to_len)) // 先构建一个hash表,用php伪代码来解释第一种情况构建好的hash表 // array('g'=>'g','h'=>'a','i'=>'i','w'=>'b') unsigned char xlat[256], j = 0; do { xlat[j] = j; } while (++j != 256); for (i = 0; i < trlen; i++) { xlat[(size_t)(unsigned char) str_from[i]] = str_to[i]; } // 接着遍历字符串,从hash表中找到转换的字符 for (i = 0; i < ZSTR_LEN(str); i++) { if (ZSTR_VAL(str)[i] != xlat[(size_t)(unsigned char) ZSTR_VAL(str)[i]]) { new_str = zend_string_alloc(ZSTR_LEN(str), 0); memcpy(ZSTR_VAL(new_str), ZSTR_VAL(str), i); // 从hash表中找到转换的字符 ZSTR_VAL(new_str)[i] = xlat[(size_t)(unsigned char) ZSTR_VAL(str)[i]]; break; } } for (;i < ZSTR_LEN(str); i++) { // 从hash表中找到转换的字符 ZSTR_VAL(new_str)[i] = xlat[(size_t)(unsigned char) ZSTR_VAL(str)[i]]; }}
第三种、第四种from是个数组,如果from是数组,情况就不是一对一的字符转换,是字符串对字符串的转换了,把key整个字符串转换成value字符串。
第三种,from数组只有一对键值对,实现思路是,根据kmp算法在主串中搜索key(被替换的字符串)的位置,如果找到,就使用value替换掉。kmp本身的效率是O(n),所以如果字符串内进行了m次替换,这种情况下strtr效率会是O(n*m)1234567891011// 搜索被替换的字符串的所有位置e = s = ZSTR_VAL(new_str);end = ZSTR_VAL(haystack) + ZSTR_LEN(haystack);// php_memnstr搜索 被替换的字符串 的所有位置,并替换掉for (p = ZSTR_VAL(haystack); (r = (char*)php_memnstr(p, needle, needle_len, end)); p = r + needle_len) { memcpy(e, p, r - p); e += r - p; memcpy(e, str, str_len); e += str_len; (*replace_count)++;}
第四种,通过数组替换多个字符串,这种是各种情况效率最差的1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950// 先构造所有 被替换的字符串ZEND_HASH_FOREACH_STR_KEY(pats, str_key) { len = ZSTR_LEN(str_key); // 计算所有 被替换的字符串 最长和最短值 if (len > maxlen) { maxlen = len; } if (len < minlen) { minlen = len; } // 记录每个key长度值的hash值 num_bitset[len / sizeof(zend_ulong)] |= Z_UL(1) << (len % sizeof(zend_ulong)); // 记录每个key首字符的hash值 bitset[((unsigned char)ZSTR_VAL(str_key)[0]) / sizeof(zend_ulong)] |= Z_UL(1) << (((unsigned char)ZSTR_VAL(str_key)[0]) % sizeof(zend_ulong)); } ZEND_HASH_FOREACH_END();// 辅助两个hash表,替换的字符串old_pos = pos = 0;while (pos <= slen - minlen) { key = str + pos; // 如果从首字符的hash表匹配到,表示以key[0]字符开头的有可能是被替换的字符串 if (bitset[((unsigned char)key[0]) / sizeof(zend_ulong)] & (Z_UL(1) << (((unsigned char)key[0]) % sizeof(zend_ulong)))) { len = maxlen; if (len > slen - pos) { len = slen - pos; } // key从maxlen循环到minlen,所以,第四种'hello'和'he',最先匹配到hello while (len >= minlen) { // 如果从长度hash表里面匹配到被替换的字符串里可能的长度,就从from数组里面找到替换的键值对zend_hash_str_find if ((num_bitset[len / sizeof(zend_ulong)] & (Z_UL(1) << (len % sizeof(zend_ulong))))) { entry = zend_hash_str_find(pats, key, len); if (entry != NULL) { zend_string *s = zval_get_string(entry); smart_str_appendl(&result, str + old_pos, pos - old_pos); smart_str_append(&result, s); old_pos = pos + len; pos = old_pos - 1; zend_string_release(s); break; } } len--; } } pos++;}
这种情况有点复杂,下面的php伪代码翻译一下以上的C语言代码123456789101112131415161718192021222324252627$bitset = array_fill(0, 255, 0); // 首字符的hash表$num_bitset = array_fill(0, 255, 0); // key长度值的hash值$min_len = PHP_INT_MAX;$max_len = 0;$len = 0;// echo strtr('hello world', ['he' => 'th', 'hello' => 'hi']);$pats = ['he', 'hello'];foreach($pats as $v){ $len = strlen($v); if($len > $max_len) { $max_len = $len; } if($len < $min_len) { $min_len = $len; } $num_bitset[intdiv($len,8)] |= 1 << ($len%8); $bitset[intdiv(ord($v[0]),8)] |= 1 << (ord($v[0])%8);}// print_r(array_unique($num_bitset));// print_r(array_unique($bitset));// 例如我们匹配hello,首字符是h,长度5// 以下两行就是以上C语言的while循环里面两个if判断echo $bitset[intdiv(ord('h'),8)] & 1 << (ord('h')%8),PHP_EOL;echo $num_bitset[intdiv(5,8)] & 1 << (5%8),PHP_EOL;
从抽奖活动总结系统优化
在魅族工作的时间,主要是从事抽奖活动、投票活动等网络营销活动,尤其是抽奖活动,魅族营销的成本投入还是大的,所以每次活动,参与用户都很热情,刚开始那会每次活动上线都会战战兢兢,现在是老油条了,不是说不怕,只是有经验了。应对并发的三板斧,限流、缓存、异步,下面就简单说说自己一些经验吧。
代码
检查代码有没有写出多层foreach嵌套,考虑是否有改进的空间;使用锁的地方考虑有没有死锁的可能性;请求第三方接口是否会漏掉超时限制,这点很容易被忽略,对接第三方的接口需要多点留意。
限流
大考前的检查,压测,通过压测的数据指导,调整nginx最大链接数,系统能力有限,超过最大链接数的直接拒绝请求。
限制僵尸用户,我们系统是微信授权的,使用微信的用户验证接口,可以挡掉一部分僵尸用户,联合自身的用户系统,排除刷奖用户的请求,这部分可以减少大部分流量。
应用层限制请求频率,限制单个用户一分钟内请求次数,使用redis的hash表存储用户一分钟内的请求次数,一个用户一条记录。
缓存
应用场景
对于数据量小、更新不频繁的,例如活动信息等,可以考虑用本地缓存,同时也使用redis做二级缓存,提高命中,提高缓存效率;数据量大、更新频繁、增长快的缓存数据使用redis等专用缓存服务。例如:随机获取愿望墙记录列表,通过数据库去随机获取那简直是噩梦,可以用redis的集合保存所有记录id,通过SRANDMEMBER从集合中返回随机id集,再通过id集从redis的hash表中获取每条记录的详细信息。
缓存更新
主动更新缓存,数据库数据更新后,往消息队列插入记录,后台消费程序主动更新缓存;同时添加缓存过期时间,自动淘汰缓存,双保险。
缓存击穿
缓存丢失的瞬间,并发请求下,会瞬间有多个请求到达数据库,查询同一份数据,数据库压力瞬间暴涨,解决方法,可以在请求数据库前上锁(使用redis setnx实现锁),只允许获得锁更新缓存,没得到锁的等待缓存更新后,直接从缓存获得数据。
数据库
慢查询优化
我们系统平时都会进行压测,根据压测结果和慢查询日志进行sql优化,这点展开说太多了。
分库
我们有时候会同时上几个活动,一般都把不同的活动分摊到不同的数据库上,相当于把流量分摊到不同数据库上。
主从同步
我们配有主从库,主写从读,在主从同步间隙,会遇到从库未同步完成,客户端读不到最新数据,可以在写入主库成功后,往redis插入一条记录,设置过期时间(一般为主从同步需要的时间),读取前,先读取redis,如果记录存在,就从主库返回数据。
乐观锁
抽奖活动扣除奖品数量,在并发下,如果不加保护,很容易超库,一般都使用事务进行扣除,但事务会影响数据性能,我们做法是使用版本号,更新库存的时候,只有版本号对上才能更新成功。
消息队列
对于抽奖活动,前端有转盘等过场动画的,可以使用异步的方式,达到削峰填谷的效果;投票这些不需要实时反馈结果的,也可以使用消息队列进行异步处理,消费程序在后台批量处理。使用消息队列需要保证消息不丢失,和防止重复消费消息。